Don't want to read a wall of text? Here's the audio & video overview, thanks to NotebookLM.
Recommender Systems (RecSys) are the silent chefs curating our digital diets: deciding what you buy on Amazon, what you see on your Facebook feed, what you watch on Netflix, and who you swipe on Tinder. Despite being the most profitable AI engines on the planet, they remain the unrefined "ugly dog" next to their flashy sibling, Large Language Models (LLMs). As a Product Manager for RecSys at Meta, I constantly wrestle with this contrast: why hasn't RecSys had its "ChatGPT moment"? This post unpacks the invisible barriers holding these foundational algorithms back and explores the technical leaps needed to advance the field.
The Core Thesis
The core thesis is that RecSys lag behind LLMs because they rely on collaborative filtering (CF) of semantically empty IDs rather than mathematically meaningful representations. While LLMs achieve cumulative learning and predictable scaling through stable token semantics, RecSys depend on co-engagement signals. This structural deficit causes persistent cold-start problems, popularity bias, low compute efficiency and low knowledge transfer rate. Achieving a "ChatGPT moment" in RecSys requires native integration of semantic representation to unlock zero-shot generalization, cumulative learning, and hardware efficiency.
The One Root Behind All Our Problems
Despite waves of innovation (DLRM, HSTU, Wukong), our Recommender System (RecSys) remains largely a collaborative filtering (CF) engine where engagement drives visibility.
If user A and user B both like car videos, and B also likes sports videos, the system will recommend sports videos to A. The model learns from patterns of co-engagement, not from the actual content.
Key hypothesis: all these issues stem from a single root cause, the lack of semantic representation in CF training. Unlike LLMs, where tokens have semantic relationships, our content is just a collection of unlinked IDs. There's no inherent relationship between two similar videos, even if they only differ by one title word. And each new content ID is a blank slate.
A semantic representation is a way of encoding information so that its meaning and relationships to other concepts are captured mathematically.
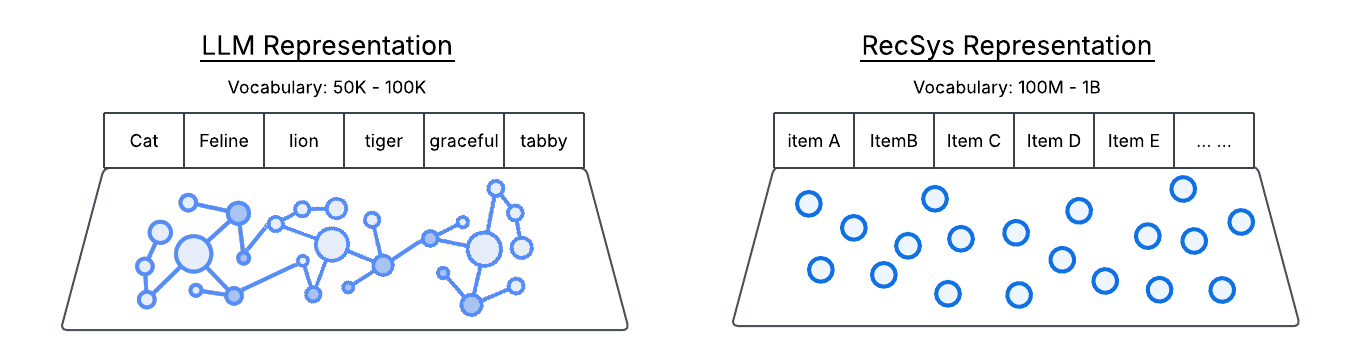
For example, in language models, words like “cat” and “feline” are represented as vectors that are close together in space, reflecting their similar meanings. This allows models to understand, generalize, and transfer knowledge based on meaning—not just on surface patterns or arbitrary IDs.
“But wait! We do have a lot of knowledge/semantic understanding for content and users?!”
While we do have semantic features, they’re not natively integrated into CF training, but more as auxiliary features or side input. Today, CF fundamentally operates on interaction patterns between meaningless IDs. Adding semantic features as side inputs is like giving a dictionary to someone who’s already learned to communicate in random symbols - it doesn’t change the foundation.
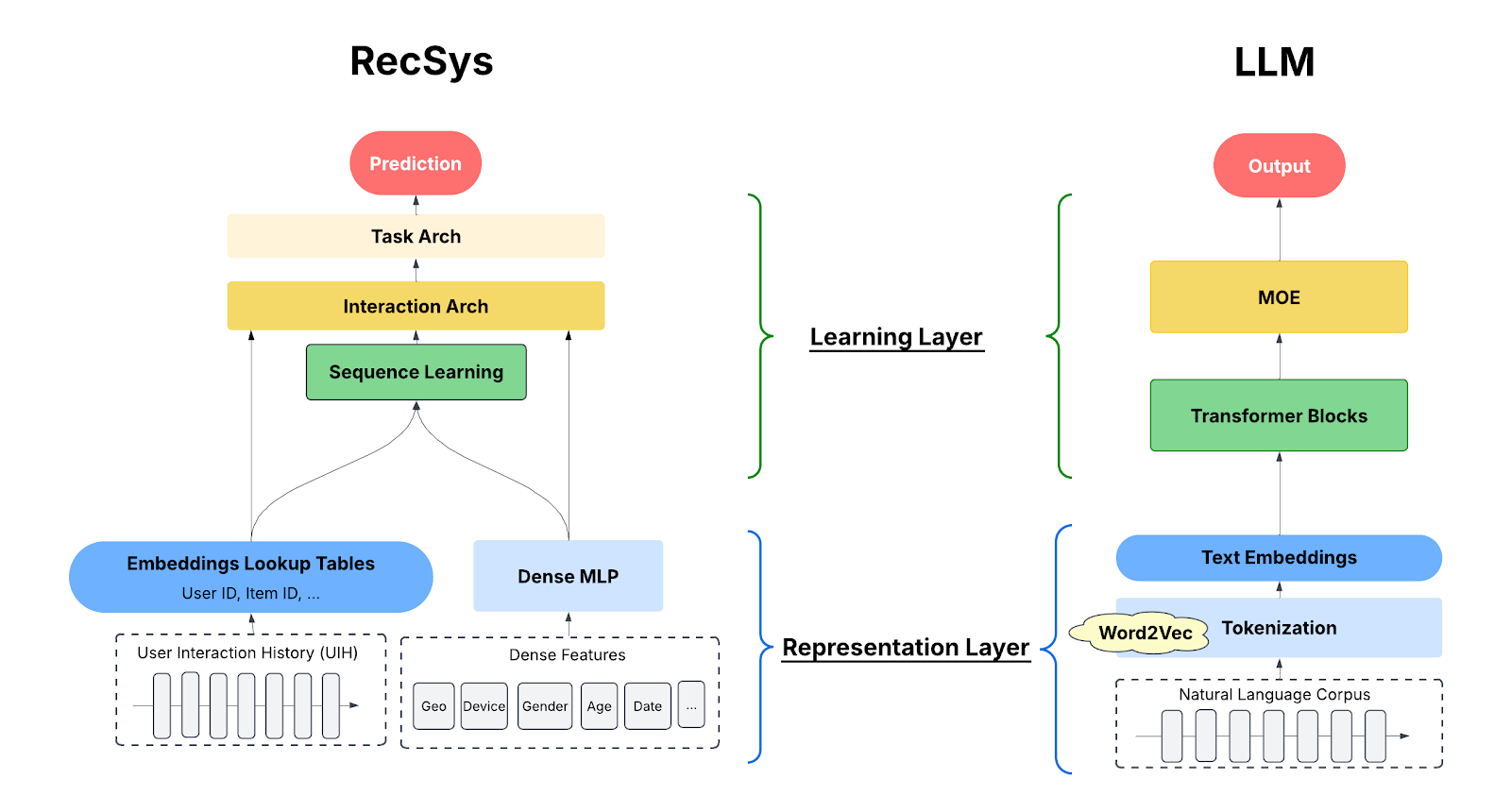
LLMs vs. RecSys: The Representation Gap
The chart below is a (grossly) simplified comparison of RecSys and LLM model architectures. The key point is that, Both RecSys and LLMs have two core components:
- The representation layer converts real-world knowledge into mathematical form.
- The learning layer identifies and encodes patterns in model parameters.
The key difference: LLMs solved the representation problem early on (e.g., word2Vec), but RecSys never did.
LLM success wasn't just about the Transformer architecture that’s the center of attention (pun intended). It was built on solving semantic representation first:
- Word2Vec (2013) - this representation breakthrough transformed words from arbitrary symbols into meaningful vectors. "King" - "Man" + "Woman" ≈ "Queen" showed semantic relationships could be learned mathematically, creating the meaningful vocabulary that made everything else possible.
- Transformers Architecture (2017) unlocked scalable learning over those representations using self-attention.
With these building blocks, LLMs unlocked the scaling law: it’s like a person studying and building a well-organized library: every new book about a "feline" strengthens the model’s understanding of "cats." Because the representations are stable and meaningful, each new piece of knowledge accumulates and transfers through continuous token-level learning. Learning compounds and performance improves, leading to the emergence we see in LLMs.
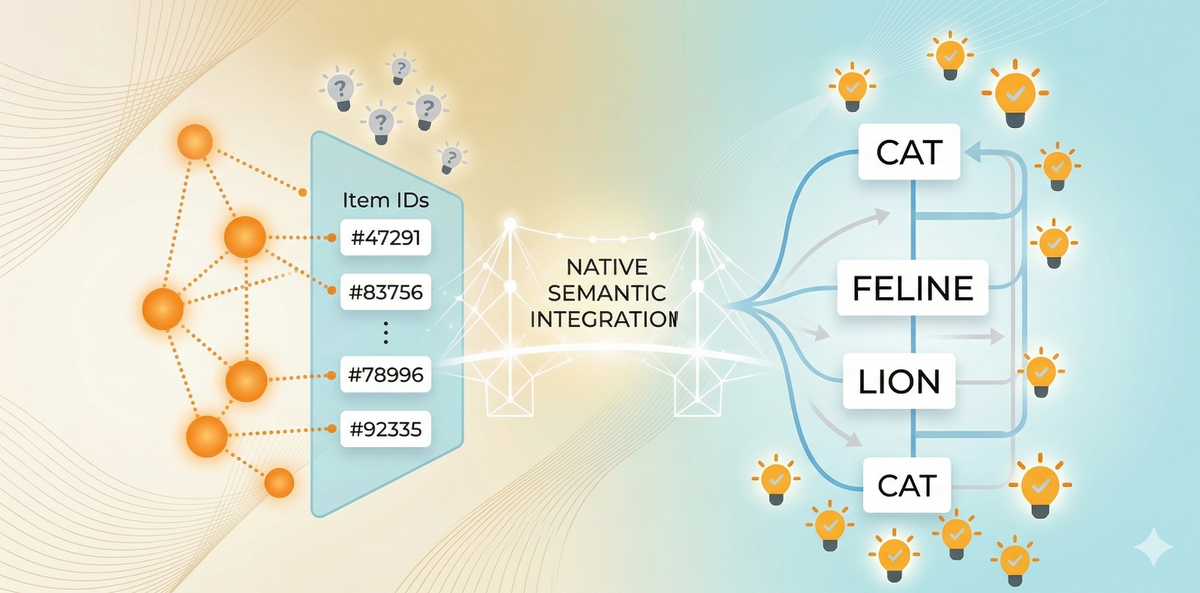
In contrast, RecSys has built powerful architectures but never solved the fundamental representation problem. The sparse embeddings reflect only interaction history, not actual meaning. It’s like trying to build ChatGPT with words as random numbers—“cat” might be ID #47291 and “feline” ID #83756, with no connection between them. To make matters worse, the vocabulary is constantly changing. As a result, RecSys can’t accumulate or transfer knowledge, regardless of how advanced the architecture becomes.
The Representation Gap Explains A Lot
The lack of semantic representation directly underlies many of RecSys’s persistent shortcomings, especially compared to LLMs:
- Cold-start & Popularity Bias: When new content, like a cute kitten video, is added, it has no semantic link to past cat videos. Without prior engagement, new content remains undiscovered: no interaction, no distribution. This mechanical dependency structurally suppresses diversity and artificially amplifies already-popular items.
- Always-On Retraining: The continuous influx of semantically empty IDs requires perpetual model retraining from scratch, precluding cumulative learning.
- Low MFU (Model FLOPs Utilization): Large, sparse embedding tables store hundreds of millions of unrelated IDs, so most GPU time is spent fetching data rather than computing, keeping MFU low. RecSys MFU hovers around 4–30%, versus ~40% for LLMs.
- Weak scaling laws: Adding more compute or parameters doesn’t yield predictable improvements, since the model is just memorizing IDs instead of accumulating reusable patterns.
- Low knowledge transfer: LLMs reuse ~80% of learned knowledge; RecSys manage ~30–40%.
This also explains why extending User Interaction History (UIH) consistently improves performance: UIH is the most reliable predictor, not due to true understanding, but because it’s one of the few stable sources of correlation when IDs lack meaning.
The "ChatGPT Moment" for RecSys
The industry has recognized this missing building block and is acting fast. For RecSys, a "ChatGPT moment" is not necessarily about achieving conversational fluency in the literal sense. Rather, it signifies the attainment of emergent properties that have long been the domain of advanced AI: zero-shot generalization, deep semantic reasoning, and, most critically, the capacity for cumulative learning. Now imagine a RecSys that truly understands the meaning behind users’ interactions and accumulate this knowledge:
- Cold start and Long tail Challenges: When a cat video is added, RecSys instantly knows which users are likely to enjoy it; Niche content can find its audience based on meaning, not just engagement history.
- Popularity bias: Based on semantic meaning, recommendations can diversify, surfacing relevant but less-engaged content.
- Less retraining: Better generalization means less reliance on always-on retraining, reducing costs.
- Higher MFU: Smaller embedding tables mean more efficient compute, increasing MFU from 8% to 40% means a 80% GPU savings.
- Scaling laws: With stable semantic representation, adding compute/parameters could unlock predictable improvements.
- Higher knowledge transfer: Foundation models could generalize knowledge to new items and smaller models, driving further efficiency.
